
Slack pingar, ett möte dyker upp och en kollega vill ha en code review. Arbetsdagen är full av kontextbyten och mitt i allt ska de där små återkommande uppgifterna fortfarande bli gjorda. Känner du igen dig?
Det här är berättelsen om hur vi automatiserade bort en sådan uppgift. Jag är för närvarande konsult på ett stort svenskt medieföretag där jag är produktägare för DataOps-teamet. I rollen ingår bland annat statusrapportering.
Varannan vecka ska någon i varje produktteam skriva en sprintsammanfattning och posta den i pulse-kanalen på Slack. Det är en liten uppgift på pappret men den innebär en del friktion i praktiken. Man måste komma ihåg att göra det. Man måste gå igenom trello-boarden och sammanfatta två veckors arbete till något som är både kortfattat och tydligt. Och om man är på semester så blir det oftast inte gjort.
I DataOps-teamet bestämde vi oss för att automatisera bort det problemet. Inte med ett avancerat AI-agentramverk utan med ren Python, en Trello-board vi redan använde och en LLM som skriver utkastet åt oss. Resultatet är en Slack-bot som reducerar det manuella arbetet till en snabb granskning. Och som aldrig glömmer att köra.
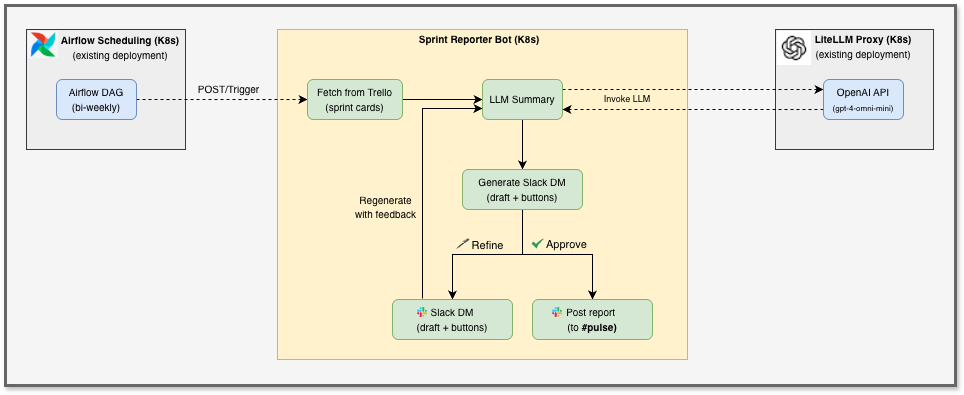
Arkitektur
Eftersom vår bot inte är någon autonom agent som fattar egna beslut så behövde vi inte använda något komplext ramverk för AI-agenter. Arkitekturen bygger på enkelhet, den består av en linjär pipeline i tre steg:
- Hämta kort från Trello
- Be en LLM sammanfatta dem som ett utkast
- Skicka utkastet till en människa för granskning i Slack
Boten är byggd med fem beroenden: slack-bolt, httpx, openai, flask och python-dotenv. Ungefär 150 rader applikationskod.
Hela pipelinen är tre funktionsanrop:
def run_pipeline(config: Config) -> str:
sprint_data = get_sprint_data(config) # 1. Fetch from Trello
summary = generate_summary(sprint_data, config) # 2. LLM summarization
send_draft(summary, sprint_data, config) # 3. Send slack DM for review
return summary
Två komponenter
Systemet består av två delar:
En långkörande Slack-bot som kör som en container i vårt on-prem Kubernetes-kluster. Boten hanterar interaktiva meddelanden och exponerar en enkel HTTP-endpoint för att trigga rapportgenerering.
En Airflow-DAG med schemalagd körning varannan vecka. Dess enda uppgift är att POST:a till botens /trigger-endpoint. Eftersom teamet redan kör alla datapipelines i Airflow var det ett naturligt val att schemalägga även detta jobb där. Det ger oss körhistorik och tydlig status för lyckade respektive misslyckade körningar.
Trello-integrationen
Trellos REST API är rakt på sak. Vi definierar en mappning från kolumnnamn till kategorier, hämtar alla listor på boarden och plockar ut korten från varje matchande kolumn:
TARGET_LISTS = {
"Done": "done",
"Review": "review",
"Ongoing": "ongoing",
"Blocked": "blocked",
"Sprint Backlog": "next",
}
def get_sprint_data(config: Config) -> dict[str, list[Card]]:
result = {"done": [], "review": [], "ongoing": [], "blocked": [], "next": []}
with httpx.Client(timeout=30) as client:
# Get all lists on the board
board_lists = client.get(
f"{TRELLO_API}/boards/{config.trello_board_id}/lists",
params=auth,
).json()
# Match target columns by name, then fetch their cards
for lst in board_lists:
if lst["name"].strip() in TARGET_LISTS:
category = TARGET_LISTS[lst["name"].strip()]
cards = client.get(
f"{TRELLO_API}/lists/{lst['id']}/cards",
params={**auth, "fields": "name,desc"},
).json()
for card in cards:
result[category].append(Card(name=card["name"], description=card.get("desc", "")))
return result
Från varje kort läser vi namn, beskrivning och epic-etikett. Detta är tillräckligt med kontext för att LLM:en ska ha något meningsfullt att jobba med.
LLM-sammanfattningen
Vi routar alla LLM-anrop via en befintlig LiteLLM-proxy med hjälp av OpenAI Python SDK. Det ger oss flexibilitet, vi kan byta mellan olika språkmodeller bakom proxyn utan att röra applikationskoden.
Systempromten är medvetet kompakt. Strama prompter ger oftast konsekvent output:
SYSTEM_PROMPT = """\
You are a concise technical writer helping a product owner report on the team's sprint progress.
...
Rules:
- Write 3-6 bullet points.
- Cards have labels (e.g. Data quality) representing the epic they belong to. \
First, identify all unique epics across all cards. Then write exactly one bullet per epic, \
merging all cards from that epic into a single bullet regardless of which column they are in. \
A bullet for one epic should cover its done, ongoing, and upcoming work in one or two sentences.
- Weave the epic topic naturally into the sentence rather than phrases like
"from the X epic" — for example, write "Completed the data quality monitoring dashboard" \
not "Completed the monitoring dashboard Epic: Data quality".
- Cards without labels can be grouped into a single "other" bullet.
- Do not include card descriptions verbatim — synthesize and summarize.
- Output only the bullet list, nothing else (no heading, no sign-off).
"""
Själva LLM-anropet är minimalt, openai-SDK:t pekat mot vår LiteLLM-proxy:
def _get_client(config: Config) -> OpenAI:
return OpenAI(base_url=config.llm_base_url, api_key=config.llm_api_key)
def generate_summary(sprint_data: dict[str, list[Card]], config: Config) -> str:
client = _get_client(config)
card_text = _format_cards(sprint_data)
response = client.chat.completions.create(
model=config.llm_model,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Here are the current sprint cards:\n\n{card_text}"},
],
temperature=0.3,
)
return response.choices[0].message.content.strip()
Människan i loopen
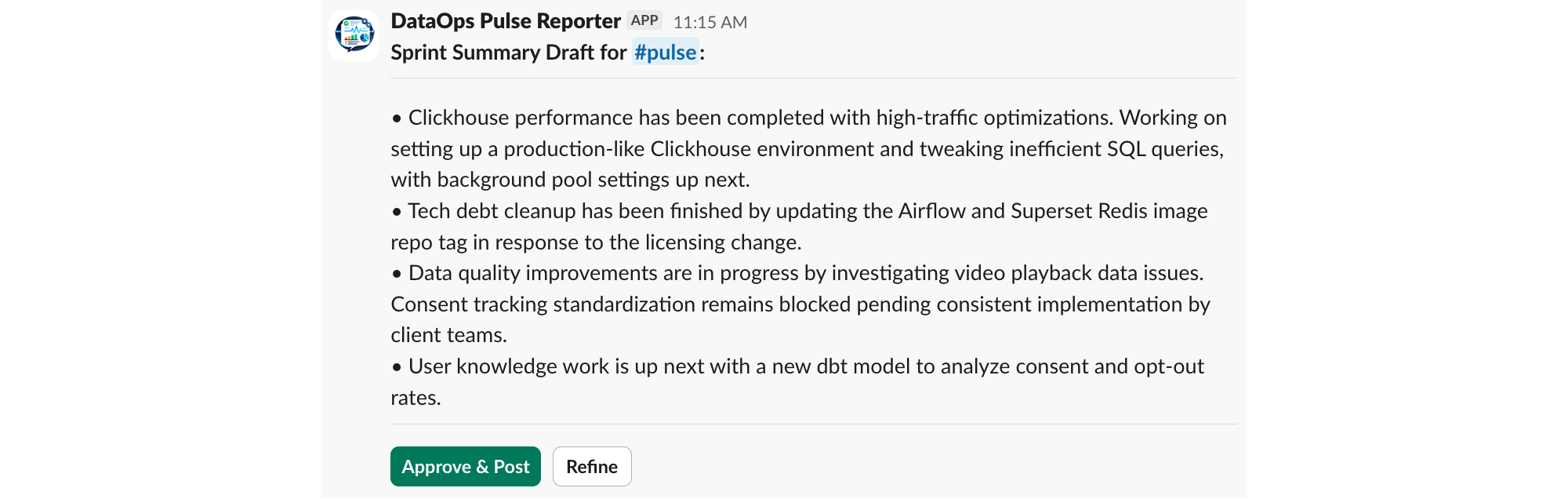
Det är här designen blir intressant. Boten postar aldrig direkt i pulse-kanalen. Varje sammanfattning passerar en mänsklig granskning:
- Boten skickar ett DM till produktägaren med utkastet och två knappar: Approve & Post och Refine.
- Trycker man på Refine öppnas en Slack-modal där man skriver feedback. Tex “gör första punkten mer specifik” eller “lägg till migreringsarbetet”.
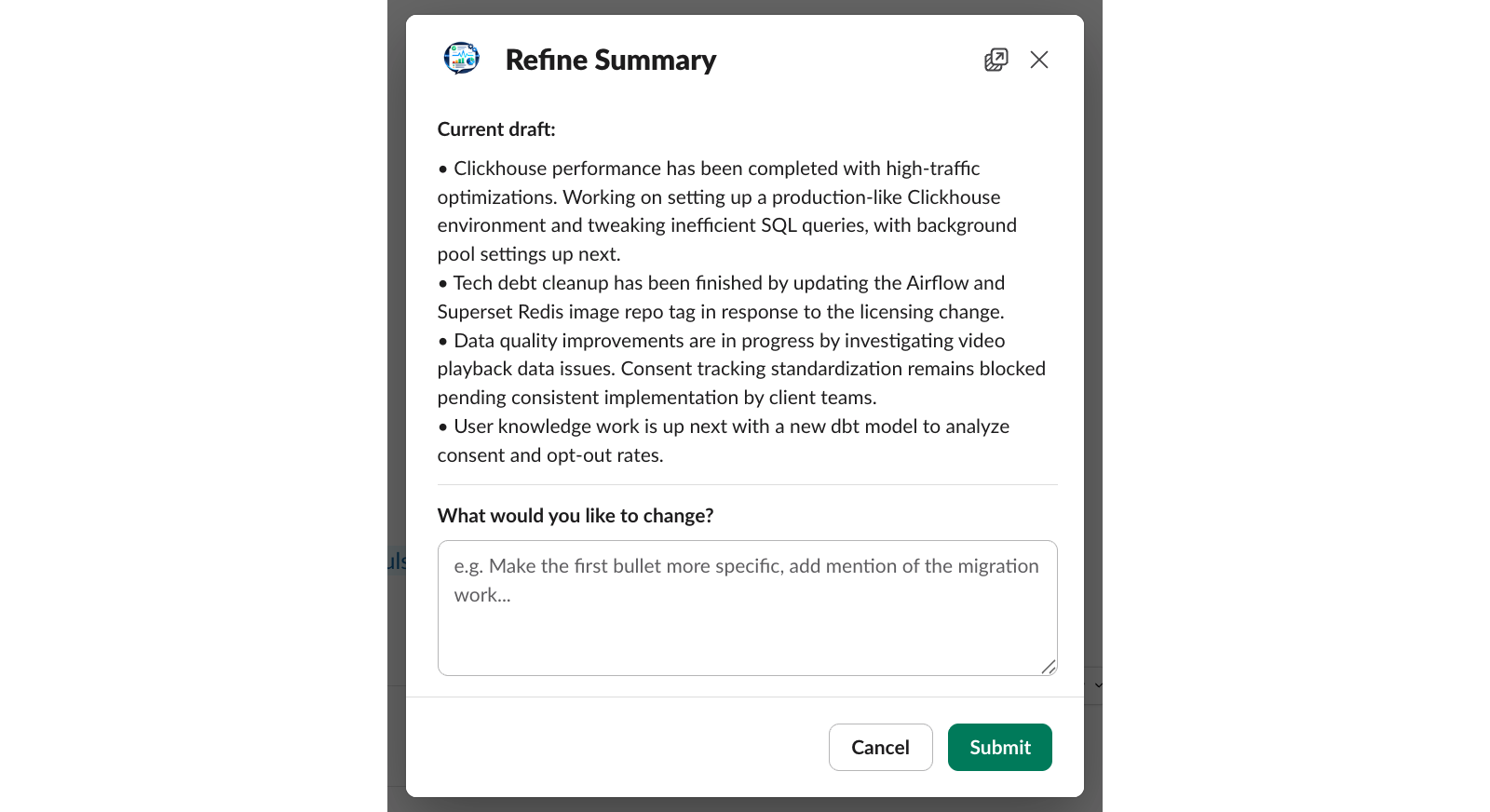
LLM:en genererar om sammanfattningen med feedbacken som kontext, och DM:et uppdateras direkt med det reviderade utkastet och nya knappar.
Man kan förfina så många gånger man vill. När sammanfattningen ser bra ut klickar man på Approve & Post.
Den godkända sammanfattningen postas i rapportkanalen som produktägaren via en User OAuth Token. Det innebär att det är ett vanligt inlägg som ägaren kan redigera eller radera i efterhand. Varje inlägg inleds med teamnamn, ikon och uppdrag, följt av det AI-genererade innehållet.

Koden för förfiningsloopen:
def handle_refine_submission(ack, body, client, view):
ack()
feedback = view["state"]["values"]["feedback_block"]["feedback_input"]["value"]
# Re-generate with the original Trello data + user feedback
new_summary = refine_summary(
current_summary=_active_draft.summary,
feedback=feedback,
sprint_data=_active_draft.sprint_data,
config=_config,
)
_active_draft.summary = new_summary
# Update the DM in place with the revised draft and fresh buttons
client.chat_update(
channel=_active_draft.channel_id,
ts=_active_draft.message_ts,
blocks=_build_draft_blocks(new_summary),
)
Förfiningsloopen är det som gör verktyget faktiskt användbart. En LLM-sammanfattning av Trello-kort ger ett hyggligt första utkast, men det är sällan felfritt. Kanske betonar den fel sak. Att kunna iterera direkt i Slack, utan att hoppa till ett annat verktyg, förvandlar ett utkast till en polerad uppdatering på under en minut.
Kubernetes utan publika endpoints
Ett arkitekturbeslut som förenklade driftsättningen markant är användningen av Slacks Socket Mode. Traditionella Slack-appar kräver en publikt nåbar URL för att ta emot events och interaktioner. I ett on-prem Kubernetes-kluster bakom en företagsbrandvägg innebär det antingen nätverkshål eller en kedja av reverse proxies.
Socket Mode eliminerar det problemet helt. Boten öppnar en utgående WebSocket-anslutning till Slack. Alla events och knappklick flödar över denna persistenta anslutning. Den enda inkommande trafiken är /trigger-endpointen, som bara behöver vara nåbar inifrån klustret (av Airflow).
Kubernetes-uppsättningen är minimal: en deployment med en replica, en service för /trigger-endpointen och miljövariabler från en secret.
Startpunkten kör HTTP-triggern och Slack-lyssnaren i en och samma process:
def main():
config = load_config()
slack_app = create_app(config)
# Flask HTTP server in a background thread (for Airflow to call)
flask_app = create_flask_app(config)
flask_thread = threading.Thread(
target=lambda: flask_app.run(host="0.0.0.0", port=config.trigger_port, use_reloader=False),
daemon=True,
)
flask_thread.start()
# Slack Socket Mode in the foreground (outbound WebSocket — no ingress needed)
start_socket_mode(slack_app, config)
Airflow-DAG:en som triggar den:
with DAG(
dag_id="pulse_report",
schedule_interval="0 10 */14 * *", # Every two weeks at 10:00
catchup=False,
tags=["dataops", "reporting"],
) as dag:
trigger_draft = SimpleHttpOperator(
task_id="trigger_pulse_draft",
http_conn_id="pulse_reporter_bot",
endpoint="/trigger",
method="POST",
response_check=lambda resp: resp.json().get("status") == "ok",
)
Möjliga förbättringar
Persistent state. Boten håller sitt utkast i minnet. Om containern startar om mellan att utkastet skickas och att det godkänns försvinner det och måste triggas igen. För ett arbetsflöde med en användare och ett utkast åt gången är det en acceptabel avvägning men lagring i Redis eller SQLite hade gjort systemet mer motståndskraftigt.
Stöd för flera kanaler. Nuvarande design utgår från ett team, en Trello-board och en Slack-kanal. Att generalisera det för fler team kräver routinglogik och per-team-konfiguration, ett naturligt nästa steg om intresset finns.
Slutsats
De mest användbara automatiseringarna är inte alltid de mest sofistikerade. Vi behövde ingen autonom agent. Vi behövde tre API-anrop i sekvens, en välformulerad prompt och ett flöde med en människa i loopen.
LLM:ens roll är smal och väldefinierad: ta strukturerad data och producera läsbar text. Det är en uppgift där även mindre modeller levererar bra resultat.
Ungefär 150 rader Python. Fem beroenden. En Trello-board vi redan hade. Och rapporten skriver sig själv — i alla fall nästan 😉
Har du liknande eller andra utmaningar i din verksamhet, eller har du löst dem på ett annat sätt? Vi berättar gärna mer om implementationen eller bollar idéer, hör av dig till hej@artofcode.se
